Machine Learning Training for Automatic Target Detection
Anonym
This blog offers a deeper dive into the machine learning training process for performing automatic target detection. Samples of automatic target detection were recently presented at the Machine
Learning: Automate Remote Sensing Analytics to Gain a Competitive Advantage
webinar.
Machine learning (ML) applications, from object recognition
and caption generation, to automatic language translation and driverless cars,
have increased dramatically over the last few years, powered mainly by the
increase of computing power (using GPUs), reduced cost of storage, wider availability
of training data, and development of new training techniques for the machine learning models.
In the last five years, Harris Corporation has made a
multi-million dollar investment into applying machine learning to solve
customer challenges using remote sensing data. In response to the increased
interest from our customers in evaluating how machine learning can solve their
problems using geospatial data, I set out to train some of my coworkers on how to build a ML model to perform automatic feature detection
on 2D overhead imagery. This training was crucial for our Solutions Engineers (SEs) to be able to prototype custom solutions for our customers and/or to integrate
Machine Learning with our other powerful image analytics software like ENVI/IDL.

Figure 1: From left to right, Jeff
McKissick, Zach Norman, Pedro Rodriguez, Rebecca Lasica, and Dan Platt are
pictured here in the lobby of the Harris Broomfield, CO office
For this particular automatic target detection training, I
chose to build a ML classifier to identify all the crosswalks in a subset image
of São Paulo, Brazil. São Paulo is notoriously known for congested streets and
woefully unfriendly streets for pedestrians, often lacking zebra-type crosswalk
markings. This application demonstrates how city officials can use ML to automatically find all the crosswalks in the city for urban
planning purposes. As an example, by knowing where crosswalks are it can be
used to determine the number of missing crosswalks and accurately gauge the
amount of labor and material required in order to increase pedestrian safety.
In just a few hours, and with each trainee using a small Red
Hat Virtual Machine of 4GB RAM and 2 CPUs, we were able complete the
entire process, from gathering the training data, building the ML model, and
finally classifying a subset of the selected raster dataset.
For the raster dataset we used a high resolution satellite
image from DigitalGlobe, Inc. (0.3 GSD, 4-band (RGBN), WorldView-3) from São
Paulo, Brazil. To gather the training data (positives and negatives), we used a
custom ENVI extension to chip 35x35 pixels samples and augment the training
data as shown in Figure 2 below.
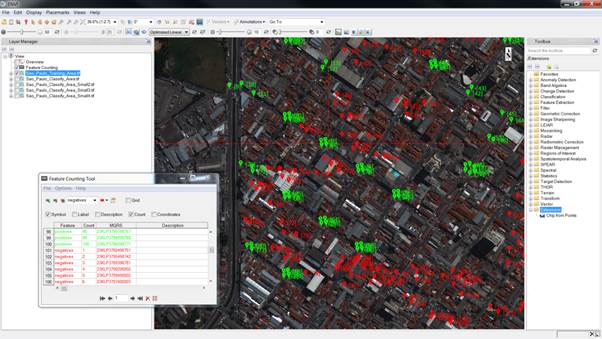
Figure 2: “Chip From Points” ENVI
extension to gather training data
For data augmentation, we simply rotated each image chip 90
degrees (4 rotations). For the sake of time, we only selected 100 positives and
200 negatives, which after the data augmentation we had 1,200 training chips
(400 positives and 800 negatives). From the 1,200 training chips 10% were used
for validation, 20% for testing, and 70% for doing the actual training of ML
model. As seen in the heatmap shown in Figure 3 below, the ML
classifier resulting from the limited training dataset (1,200 samples x 70%
training = 840 training samples) performed very poorly as it contained many
false negatives (missed detections) and some false positives (wrong detections).

Figure 3: Heatmap from a ML
classifier using 100 positives and 200 negatives with 4 rotations
In order to highlight the true potential of our ML
technology, I decided to train the crosswalk classifier with a larger training
data set. For this, I increased the training data by 5 times, so instead of
just having 100 positives and 200 negatives, the new training set had 500
positives and 1,000 negatives. I also rotated each image chip by 10 degrees (36
rotations) instead of just every 90 degrees (4 rotations) which augmented the
total image samples to 54,000. Table 1 below summarizes the data set
used in both cases.
Table 1: Date Set
Characteristics
|
Data Set
|
Positives
|
Negatives
|
Rotations
|
Total Samples
|
Training Samples (70%)
|
|
Small
|
100
|
200
|
4
|
1,200
|
840
|
|
Large
|
500
|
1,000
|
36
|
54,000
|
37,800
|
The next step was to determine the number of iterations
(mini-batch updates) that were needed to complete an epoch. One epoch consists
of one full training cycle on the training data set. To calculate iterations
per epoch we use the following formula:
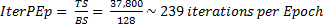 where,
where,
TS =
Training Samples and,
BS = Batch
Size
It’s difficult to prescribe a minimum number of epochs for
training a new model since it will vary depending on the difficulty of the
problem, quality of the data, chosen network architecture, etc. As a starting
point, I began with 42 epochs and to calculate the total number of iterations I
used the following formula:
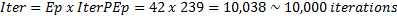
The required number of epochs can be determined by watching
the validation accuracy as the training proceeds with increasing number of
iterations. This validation accuracy can be plotted with IDL as Receiver
Operating Characteristic (ROC) curves as seen in Figure 4 below:
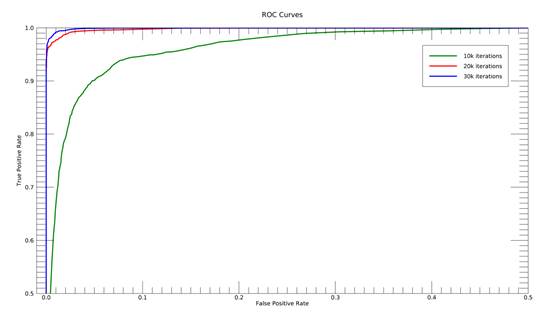
Figure 4: ROC Curves with 10k, 20k,
and 30k iterations
ROC curves feature false positive rate on the X axis and
true positive rate on the Y axis. This means that the top left corner of
the plot represents the “ideal” Machine Learning classifier, which has a false
positive rate of zero, and a true positive rate of one. It can be seen from Figure
4 above, that the accuracy of the crosswalk classifier increased
with the number of iterations. At 30,000 iterations (about 126 epochs), the ROC
indicated that enough training was achieved with an overall accuracy (ACC) of
98.84%. Figures 5 and Figure 6 below show the results of the 30k
iteration classifier in a dense urban scene and in a highway scene,
respectively. This crosswalk classifier proved to be very robust against confusers,
like other similar street marking, and occlusions, like partially hidden
crosswalks in the shadows. I challenge you to find the crosswalks manually in
the “before” (left) scenes of Figures 5 and Figure 6. You can
later validate your answers in the “after”(right) scene that was analyzed using
ML. Can you imagine manually identifying all the crosswalks in the
city of Sao Paulo?
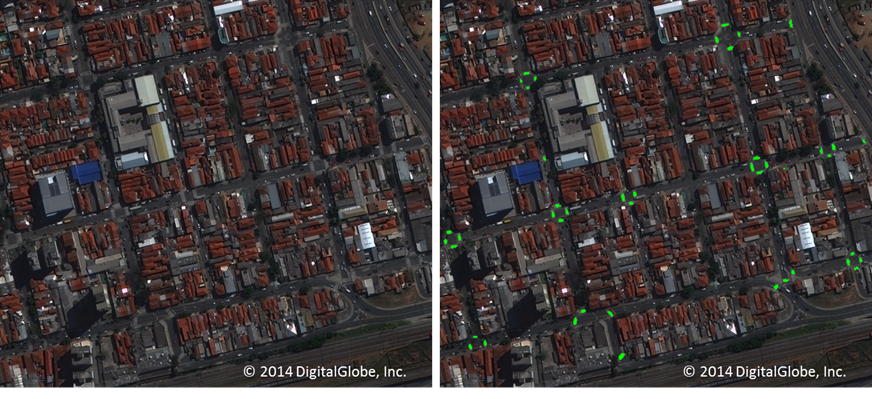
Figure 5:
Urban Scene, before and after crosswalk detection

Figure 6:
Highway Scene, before and after crosswalk detection
Automatic target detection is
one of our most basic ML solutions, which usually involves searching for
particular features in a large dataset, therefore applicable to many real world
challenges. This type of solution is even more relevant with the “Big Data”
surge in which studies indicate that only 0.5% of all data generated gets ever
used or analyzed (1). It is clear that future business advantages in every
industry will arise when companies are able to automatically analyze this surge
of data. Machine Learning is not meant to replace industry professionals, but
to off load some of the tedious task to the computer, so they can focus their
expert attention to analysis and not on “snailing” large datasets searching for
particular features. ML can also run 24/7 and is highly scalable to available
computing resources.
I want to emphasize that at Harris Corp. we are not merely
delivering software on disk, but an end-to-end solution to deliver answers to
specific industry problems. To answers questions like, “How many utility poles
need servicing?” “Which blades in a wind farm have damage?” or “How are the
road conditions near me?” All of these are questions we have been able to
accurately answer for our customers.
If you would like to know more about how we have implemented
Machine Learning to address other real-world problems, watch the webinar
that my co-worker Will Rorrer and I hosted in January 2017: MachineLearning: Automate Remote Sensing Analytic s to Gain a Competitive Advantage
Download a printer-friendly PDF of this blog here.
For any other questions, please contact our Software Sales
Manager:
Kevin Wells
Kevin.wells@harris.com
Office:
303-413-3954
References:
(1)
https://www.technologyreview.com/s/530371/big-data-creating-the-power-to-move-heaven-and-earth/