ENVI and IDL Services Engine : Getting Maximum Performance
Background
For the past 30 years, NV5 Geospatial has been delivering premier scientific data analysis tools and solutions to researchers, analysts, and businesses through the IDL and ENVI platforms. ENVI and IDL are maintained and developed to meet the needs of the broad community of users for both analytics and system capabilities. As users scale their work to enterprise and cloud deployments, the Services Engine provides ENVI and IDL processing functionality as RESTful web services for online and on-demand scientific data analysis. The Services Engine is middle-ware agnostic, adheres to open standards, supports multiple clients (web, mobile, desktop) and is highly-configurable. As with all large scale deployments in the enterprise, on clouds, or across clusters, performance gains and possibilities can scale differently in each case and can be impacted by architectural decisions. This white paper describes the performance gains possible with the ENVI and IDL Services Engine, how best to maximize those gains, and situations that may limit those gains.
Problem
The size and scope of current questions in scientific and commercial data applications demand data sets and analytics that are too large to be handled in a practical way even by high-end desktop machines. Additionally, traditional supercomputing machines are often impractical for a variety of cost and resource considerations. Enterprise and cloud implementations, however, can allow users to get high power computational resources using existing groups of desktop machines, pooled systems, or PAYGO clouds and clusters such as Amazon Web Services.
Performing large scale analysis and problem solving is more complicated than just running desktop code on many machines. Consideration must be made for the overhead of splitting and recombining parallel tasks, managing resources, and how to store and access data across a network without unnecessarily copying or moving information. Maximizing the gains of performing analytics in enterprise or cloud implementations requires structuring both data and analysis in such a way as to benefit from the many-worker approach.
IDL and ENVI Services Engine Benchmarks
NV5 Geospatial performed three test cases to provide benchmarks for how best to maximize performance in a Services Engine implementation. The Services Engine uses the concept of Master and Worker nodes. Machines can have any number of worker nodes on them, allowing for optimal configuration based on the number of CPUs and cores as well as the type of tasks to be performed. One Master node supervises and organizes all worker nodes and tasks.
Testing Scenarios
Tasks
Three different tasks, representative of actual use cases, were used in this test case:
Non-process and non-disk intensive
- Exercises framework overhead
- Chosen task: addition of two numbers
- Input data: two integers
File I/O intensive
- Exercises disk bottleneck
- Chosen task: Gain/Offset
- Input data: spatial subset ([0,4409,0,3522]) of a Worldiew-2 dataset
CPU intensive
- Exercises heavy processing
- Chosen task: FFT
- Input data: spatial subset ([0,4409,0,3522]) of a Worldiew-2 dataset
Data
Input raster is a locally stored Worldview-2 panchromatic TIFF dataset, 052310279180_01_P001_MUL\10JAN19161609-M1BS-052310279180_01_P001.TIF
Dimensions: 8820 x 7046 x 8 [BSQ]
Data Type: Byte
Size: 499,573,534 bytes
Product Type: Basic1B
Projection: *RPC* Geographic Lat/Lon
Datum : WGS-84
Pixel : 0.000023 x 0.000022 Degrees
Hardware:
Master Node
CPU
- AMD Opteron Processor 6174
- 12 cores x 4 sockets = 48 cores at 2.2 GHz
128 GB RAM
Worker Node
- Intel Xeon E5-2670
- 8 cores x 4 = 32 cores at 2.6 GHz
- 256 GB RAM
Test Case One
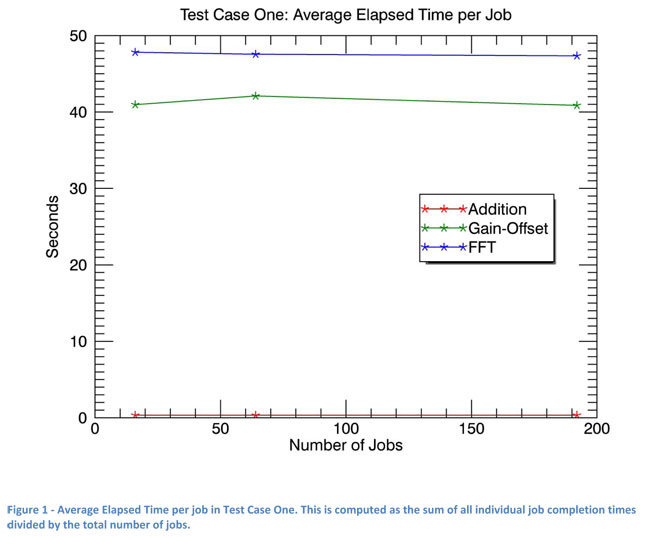
In any master/worker type of implementation, it is important that the overheard associated with the queuing, dispatching, and completing of jobs not result in the slowing of the actual job processing. The first case shows that the IDL and ENVI Services Engine does not increase overhead costs as the number of jobs increases.
The first test case used one Master node and one Worker node configured to have 4 Workers. 16, 64, and 192 jobs were submitted (workers * 4, workers * 16, and workers * 48) and times recorded for their completion. The results, as plotted in Figure 1, show that increasing the number of jobs does not change the elapsed time of individual jobs, as seen by a slope of nearly zero.
Test Case Two
With Master and Worker nodes having multiple CPUs with multiple cores, it is important to know how many workers should be configured per node. The cores can be considered independent, but they share memory, hard disk, and communication resources. While each core could theoretically be a worker, the best performance will be had when the maximum number of workers per node is set such that they do not compete for resources.
The same hardware, tasks, and data were used for this test case as in the first one, but with the number of workers per worker node varying from 2 to 4 to 8, and the number of jobs varying from 8 to 16 to 32 (workers * 4).
For the Addition task, average elapsed time per job was flat as the number of workers was increased. Effective time per job (total elapsed time divided by the number of jobs) improved slightly with the addition of workers. Worker processes did not compete for resources.
However, for the Gain/Offset task, average elapsed time per job noticeably increased with the number of workers (Figure 2). Workers competed for network and disk resources, which have maximum transfer rates and no means of controlling priorities or queuing. Those limits impacted worker elapsed time as workers waited for disk access. Workers competed for CPU time to a lesser degree than for disk access. It is important to note that effective time per job (total elapsed time divided by the number of jobs) decreased as the number of workers was increased (Figure 3). Competition for network and disk resources was the dominant factor in limiting the speed of concurrent Gain/Offset processing.
For the FFT task, average elapsed time per job as seen in Figure 2 increased with the number of workers, though not as much as seen in the Gain/Offset task. Workers competed for disk, CPU and RAM access but not to the point of thrashing. Effective time per job (total elapsed time divided by the number of jobs) dramatically decreased as the number of workers was increased (Figure 6). Individual jobs competed for disk access, but this was outweighed by time spent in the CPU. Less disk requirements, along with the native OS scheduler, allowed each FFT task to be fairly independent and staggered, improving throughput.
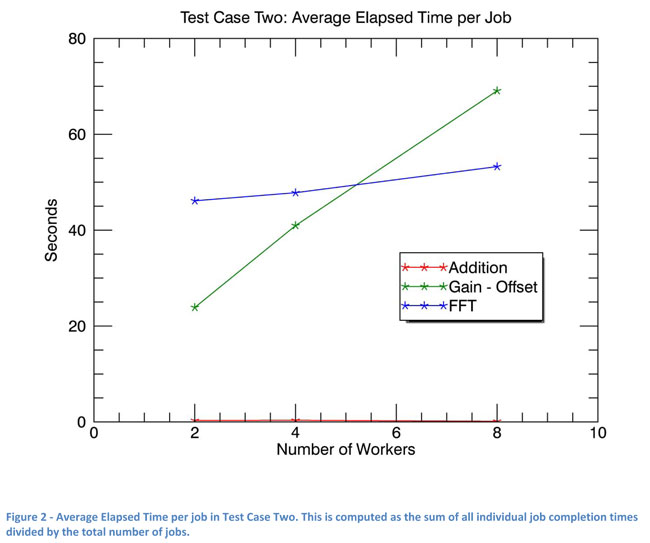
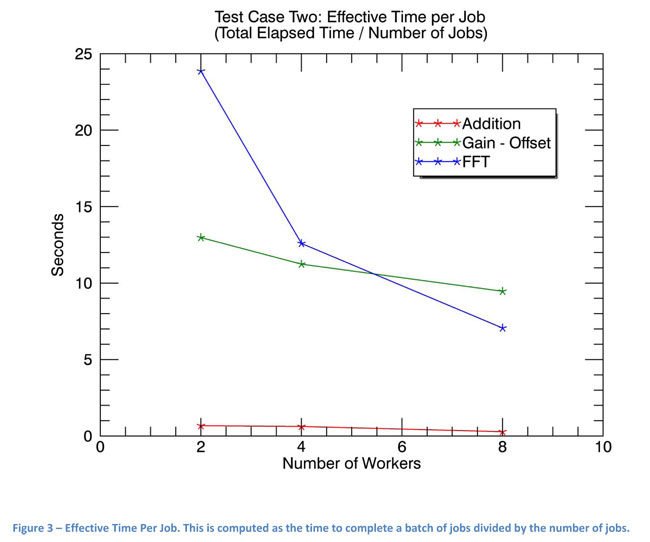
The best ratio of workers to machines or cores for each type of task depends most on the user scenario of task submission (single tasks or batch). The number of workers impacts both the average time per job and overall elapsed time of a set of jobs. Jobs individually may complete more quickly when there are fewer workers. This is especially true when the types of jobs being run compete for resources.
However, batches of jobs (throughput) complete more quickly when there are more workers, up to a point. The native operating system's scheduler and a job's varied requirements may enable jobs to interleave such that they affect each other less. In that way, a job may individually take longer, but the system's throughput can actually increase. This can be seen in Figure 2 where times for individual jobs to complete are increasing with increasing numbers of workers, but batches of job complete more quickly with more workers, as seen in Figure 3.
Inefficiencies are introduced when the lack of resources cannot be overcome by the native OS's scheduler and inherent staggering that tasks may offer. Figure 4 shows this scenario as seen on the NV5 Geospatial test cluster. The optimal throughput was achieved at the lowest point on the line, which was at 4 workers on that cluster. Beyond 4 workers, FFT job times dramatically increased as jobs competed for RAM and the operating system was eventually forced to push data out to disk via its virtual memory system (thrashing).
Test Case Three
The final test case uses the same master node, tasks, and data as the first two, but has 4 workers per worker node and varies the number of worker nodes from 1 through 4. The number of jobs varies from 8 to 16 to 32 (workers *4 * nodes). This illustrates how IDL and ENVI Services Engine job completion times scale with the size of the cluster.
A shown in Figure 4, average elapsed time for each job as the number of nodes is increased stays constant.
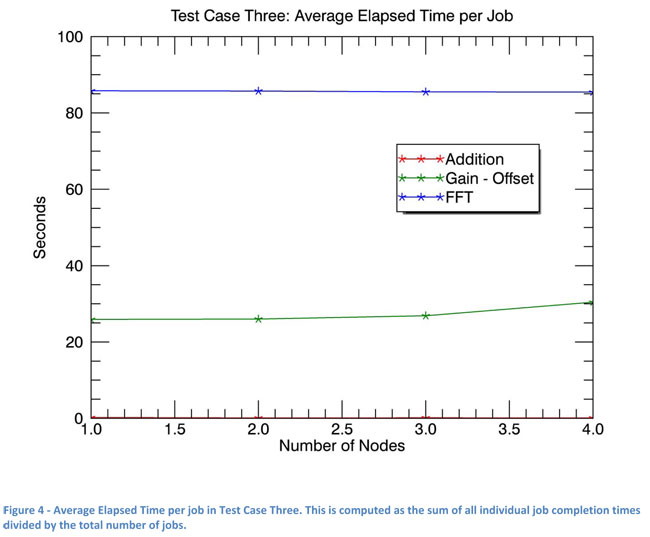
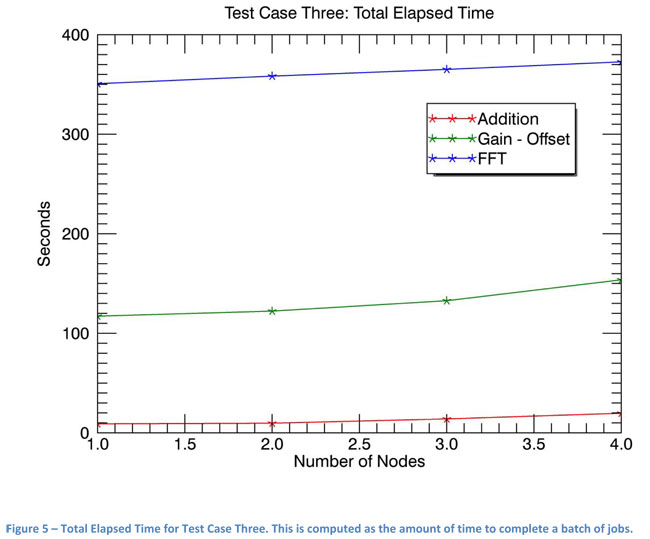
Figure 5 shows the total elapsed time per node for each task. The slight positive slope, especially in the Addition task, shows Master overhead. This shallow slope shows that ENVI and IDL Services Engine operations scale very efficiently as nodes are added to the system.
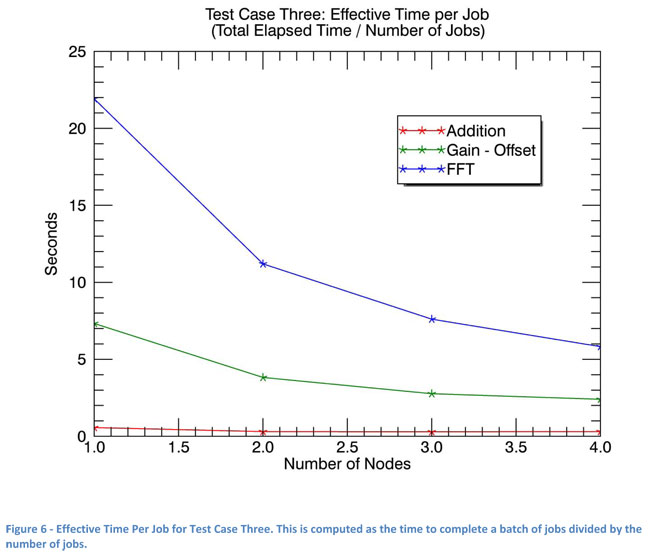
Finally, Figure 6 shows the effective time for each job decreases as worker nodes are added to the cluster, similar to the results seen in Test Case Two. This is a worst case scenario as all jobs are reading and writing to the same areas/ files on disk, which is extremely unlikely in actual application.
Summary: Maximizing IDL and ENVI Services Engine Performance
Service Engine maximum performance depends on matching the configuration to the type(s) of processing the system will be doing. Because it is both highly performant and scalable, Services Engine will make maximal use of your system. Good systems engineering will ensure one component doesn’t needlessly hamper overall performance.
- If tasks are dominantly computational in nature (e.g. image FFT), optimized data access and I/O is not a significant concern no matter how many workers are in the system.
- If the Services Engine is to be used in a traditional cluster setting, higher performance data access should be used when more than 8 workers can be expected to be performing I/O-intensive tasks.
- Solid state drives, NAS systems, and optimized RAID arrays will all help I/O intensive operations run as fast as possible on Services Engines configured to have more than 8 workers.
- When configuring a system to run Services Engine, ensure that each node has enough memory to cover the requirements of the most memory intensive task multiplied by the number of workers on that node.
IDL and ENVI Services Engine provides the bridge between desktop prototype development and accessible high-performance cloud computing. Configuring Services Engine to meet your demands will ensure maximum performance and success.