The Promise of Big Data
Big Challenges Mean Big Opportunities
Anonym
The exciting thing about big data is that it is big. At the same time, that is also the very challenge that big data presents. By definition, big data is too huge, flows at too high a velocity, is too complex and too unstructured to be processed in an acceptable amount of time using traditional data management and data processing technologies. To extract value from such data, we must employ novel, alternative means of processing it. It is in that challenge of having to follow - or create - a new way of doing things that true opportunity presents itself.
Discussions about big data often refer to the "three Vs" model of big data as being extreme in one or more aspects of volume, velocity and variety. Being big in volume means data sets with sizes that exceed the capacity of conventional database infrastructures and software tools to capture, curate, and process it. Questions of volume usually present the most immediate challenge to traditional IT practices, requiring dynamically scalable storage architectures and distributed querying and analytic capabilities.
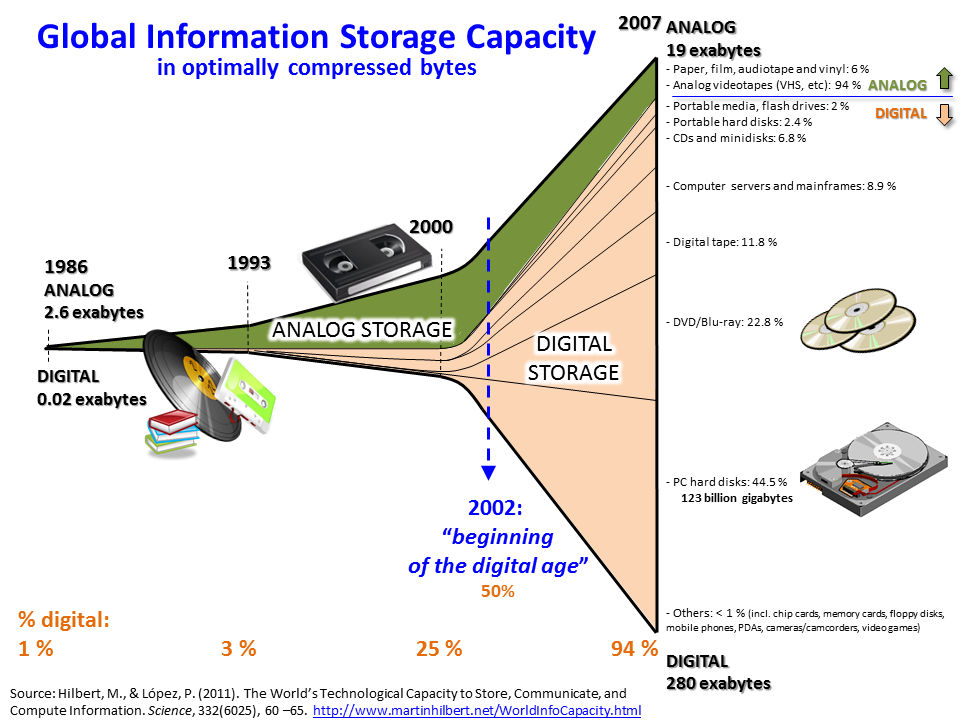 "
"
Growth of and Digitization of Global Information Storage Capacity" by Myworkforwiki is licensed under CC BY-SA 3.0
Data velocity - the rate at which data flows in and out of an organization - is following its counterpart volume along a curve of exponentially increasing growth. The driving force behind both is clearly our increasingly instrumented and sensor-infused world. Online and embedded systems are capable of capturing and compiling voluminous logs and histories of every transaction and data collection point far beyond current capabilities to effectively process them. The modern ubiquity of smart phones and mobile devices has already created a futuristic reality where every individual has the capacity to be an autonomous source of streaming image, audio and geospatial data.
It is not just the rate of data that is being taken in that is crucial when considering data velocity. What may be more important is the speed at which the calculated or derived data product can be returned, taking data from input through to decision in the feedback loop. The value of some data is intrinsically linked to its currency, rapidly losing its value with each passing moment. In order to make use of such data, a solution may need to be able to return results in near real-time. Such requirements have been a key motivation in the growing adoption of NoSQL databases.
The notion of data variety reflects the tendency of big data systems to deal with diverse, unstructured source data. Unlike traditional architectures based on highly structured data relationships, big data processing seeks to extract order and meaning from highly dissimilar, heterogeneous and disparate data streams. Text feeds from social networks, imagery data, raw signal information and emails are just a few examples of the things that a big data application draw information from.
Essentially, big data uses statistical inference and nonlinear system identification methods to infer relationships, effects and dependencies from large data sets, and to perform inductive predictions of outcomes and behaviors. We can expect that big data processing will continue to move further into the IT mainstream and benefit from the economies and efficiencies of commodity hardware, cloud architectures and open-source software. As we do so, there will certainly be no shortage of challenges needing to be overcome, and doubtless many opportunities with potential for reward.