The NCDF_VARDEF function adds a new variable to an open NetCDF file in define mode.
By default, a new NetCDF variable is chunked (meaning that the data is copied from disk into memory in discrete chunks). You can change the data chunk size with the CHUNK_DIMENSIONS keyword, or set the variable to be stored contiguously.
Examples
For more information on using NCDF_VARDEF, see Additional Examples.
In the following example, we create a NetCDF file, define its structure, and populate it with data. Click on both sections to execute the entire sample.
id = NCDF_CREATE('test.nc', /CLOBBER)
NCDF_ATTPUT, id, 'TITLE', 'Incredibly Important Data', /GLOBAL
NCDF_ATTPUT, id, 'GALAXY', 'Milky Way', /GLOBAL
NCDF_ATTPUT, id, 'PLANET', 'Earth', /GLOBAL
xid = NCDF_DIMDEF(id, 'x', 100)
yid = NCDF_DIMDEF(id, 'y', 200)
zid = NCDF_DIMDEF(id, 'z', /UNLIMITED)
vid0 = NCDF_VARDEF(id, 'image0', [yid, xid], /FLOAT)
vid1 = NCDF_VARDEF(id, 'image1', [yid, xid], /FLOAT)
dist_id = NCDF_VARID(id, 'image0')
NCDF_VARRENAME, id, vid0, 'dist_image'
NCDF_ATTPUT, id, vid0, 'TITLE', 'DIST_IMAGE'
NCDF_CONTROL, id, /ENDEF
image = CONGRID(DIST(200), 200, 100)
NCDF_VARPUT, id, vid0, image
INQ_VID = NCDF_VARINQ(id, 'dist_image')
HELP, INQ_VID, /STRUCTURE
file_inq = NCDF_INQUIRE(id)
HELP, file_inq, /STRUCTURE
NCDF_CLOSE, id
IDL prints:
** Structure <415a7d8>, 5 tags, length=40, data length=40, refs=1:
NAME STRING 'dist_image'
DATATYPE STRING 'FLOAT'
NDIMS LONG 2
NATTS LONG 1
DIM LONG Array[2]**
** Structure <412da40>, 4 tags, length=16, data length=16, refs=1:
NDIMS LONG 3
NVARS LONG 2
NGATTS LONG 3
RECDIM LONG 2
Syntax
Result = NCDF_VARDEF( Cdfid, Name [, Dim], CHUNK_DIMENSIONS=value, /CONTIGUOUS, GZIP=value, /SHUFFLE, /BYTE, /CHAR, /DOUBLE, /FLOAT, /INT64, /LONG, /SHORT, /STRING, /UBYTE, /UINT64, /ULONG, /USHORT)
Return Value
If successful, the variable ID is returned. If a new variable cannot be defined, NCDF_VARDEF returns -1.
Arguments
Cdfid
The NetCDF ID, returned from a previous call to NCDF_OPEN, NCDF_CREATE, or NCDF_GROUPDEF.
Name
A scalar string containing the variable name.
Dim
An optional vector containing the dimension IDs corresponding to the variable dimensions. If the ID of the unlimited dimension is included, it must be the rightmost element in the array. If Dim is omitted, the variable is assumed to be a scalar.
Keywords
The following keywords specify the data type for the variable. Only one of these keywords can be used. If no data type keyword is specified, FLOAT is used by default.
BYTE
Set this keyword to indicate that the data is composed of bytes.
CHAR
Set this keyword to indicate that the data is composed of bytes (assumed to be ASCII).
CHUNK_DIMENSIONS
Set this keyword equal to a vector containing the chunk dimensions for the variable.
A new NetCDF variable is chunked by default, using a default chunk value that is the full dimension size for limited dimensions, and 1 for unlimited dimensions.
CHUNK_DIMENSIONS must have the same number of elements as the number of dimensions specified by Dim.
Note: This keyword is ignored if the CONTIGUOUS keyword is set.
CONTIGUOUS
Set this keyword to store a NetCDF variable as a single array in a file. Contiguous storage works well for smaller variables such as coordinate variables.
Contiguous storage works only for fixed-sized datasets (those without any unlimited dimensions). You can’t use compression or other filters with contiguous data.
Note: If the CONTIGUOUS keyword is set, the CHUNK_DIMENSIONS and GZIP keywords are ignored.
DOUBLE
Set this keyword to indicate that the data is composed of double-precision floating-point numbers.
FLOAT
Set this keyword to indicate that the data is composed of floating-point numbers.
GZIP
Set this keyword to an integer between zero and nine to specify the level of GZIP compression applied to the variable. Lower compression values result in faster but less efficient compression.
Note: You can only use GZIP compression with NetCDF-4 files.
Note: This keyword is ignored if the CONTIGUOUS keyword is set.
INT64
Set this keyword to indicate that the data is composed of signed eight-byte integers.
Note: 64-bit integer data type can only be used within NetCDF-4 files. Use the NETCDF4_FORMAT keyword to NCDF_CREATE to create a NetCDF-4 file.
LONG
Set this keyword to indicate that the data is composed of longword integers.
SHORT
Set this keyword to indicate that the data is composed of 2-byte integers.
SHUFFLE
Set this keyword to apply the shuffle filter to the variable. If the GZIP keyword is not set, this keyword is ignored.
The shuffle filter de-interlaces blocks of data by reordering individual bytes. Byte shuffling can sometimes increase compression density because bytes in the same block positions often have similar values, and grouping similar values together often leads to more efficient compression.
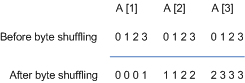
The previous diagram shows three elements of Array A, where each element variable consists of four bytes. Before byte shuffling, the three variables are represented contiguously in memory as the sequence 012301230123. After byte shuffling, all the bytes in byte position 0 are grouped together, all the bytes in byte position 1 are grouped together, and so on. Now the three variables are represented in memory by the sequence 000111222333.
STRING
Set this keyword to indicate that the data is composed of string.
UBYTE
Set this keyword to indicate that the data is composed of unsigned bytes.
UINT64
Set this keyword to indicate that the data is composed of unsigned eight-byte integers.
Note: 64-bit unsigned integer data type can only be used within NetCDF-4 files. Use the NETCDF4_FORMAT keyword to NCDF_CREATE to create a NetCDF-4 file.
ULONG
Set this keyword to indicate that the data is composed of unsigned four-byte integers.
USHORT
Set this keyword to indicate that the data is composed of unsigned two-byte integers.
Data Chunking
Overview
A data chunk is a hyper-rectangle of any size. When a dataset is chunked, each chunk is read or written as a single I/O operation, and is individually passed from stage to stage of the pipeline and filters.
Upon creation, a NCDF 4 variable is chunked by default (although you can choose to create a contiguous variable). A variable’s chunking setting is established when the variable is created, and can never be changed. You must chunk a variable that uses one or more unlimited dimensions, compression, or a filter.
Choosing Chunk Sizes
When choosing chunk sizes, you should consider:
- The dataset size
- The data size
- How the data will be read
- The operating system
Improper chunk sizes can drastically inflate the size of the resulting file or greatly slow the reading of the data. Choose a chunk size such that the subsets of data you are accessing fit into a chunk (the chunks should be as large, or larger than, the subsets you are reading/writing). For an immutable dimension, a rule of thumb is to choose a value that is evenly divisible into the dimension size. Values of less than 100 for variables with dimensions greater than 1000 can result in bloated file sizes.
When creating a NCDF 4 variable, the default chunk value is the full dimension size for limited dimensions, and 1 for unlimited dimensions. However, these values are inefficient for high-performance applications, or for very large (> 2 GB) variables.
You can improve chunking performance by ensuring the cache is large enough to hold at least one chunk. If your machine has a large amount of RAM, you can increase your chunk and cache sizes so that your program reads and writes data in large blocks.
Additional Examples
Example 2
This code sample shows how one might chunk a NetCDF 4 file dataset. Click on both sections to execute the entire sample.
Note: Wait for the first section of the code sample to complete before executing the second section (there may be a delay while reading and writing the large amount of data involved).
filename = FILEPATH('nc_chunking_test.nc', /TMP)
id = NCDF_CREATE(filename, /NETCDF4_FORMAT, /CLOBBER)
inData = BINDGEN(100, 2000)
dimx = NCDF_DIMDEF(id,'dimx', 100)
dimy = NCDF_DIMDEF(id,'dimy', /UNLIMITED)
v1 = NCDF_VARDEF(id, 'v1', [dimx, dimy], $
/BYTE, CHUNK_DIMENSIONS=[100, 10])
NCDF_CONTROL, id, /ENDEF
NCDF_VARPUT, id, 'v1', inData
NCDF_CLOSE, id
oid = NCDF_OPEN(filename, /NOWRITE)
vid = NCDF_VARID(oid,'v1')
NCDF_VARGET, oid, vid, outData
NCDF_CLOSE, oid
IF TOTAL(inData NE outData) EQ 0 THEN PRINT, $
'The data read from file is correct.'
Version History
|
Pre 4.0 |
Introduced |
|
8.0 |
Added CHUNK_DIMENSIONS, CONTIGUOUS, GZIP, and SHUFFLE keywords
|
| 8.1 |
Added STRING, INT64, UBYTE, UINT64, ULONG, and USHORT keywords |
| 9.1 |
Document INT64 keyword, add note about INT64/UINT64 keywords. |