Object detection is a method for locating features at the object level, as opposed to the pixel level. Objects are groups of pixels with similar spatial, spectral, and textural characteristics. Pixel segmentation, by comparison, locates features on a pixel-by-pixel basis. That method not only provides the locations of features but also characteristics such as shape, area, length, etc.
Object detection involves two processes:
- Locating features (objects) in an image by drawing bounding boxes around them
- Assigning each bounding box a class label
Object detection can be used to extract objects that touch or overlap, unlike pixel segmentation. ENVI uses the RetinaNet convolutional neural network (CNN) for object detection.
Reference: Lin, T.-Y., P. Goyal, R. Girshick, K. He, and P. Dollár. "Focal Loss for Dense Object Detection." http://arxiv.org/abs/1708.02002. August 2017.
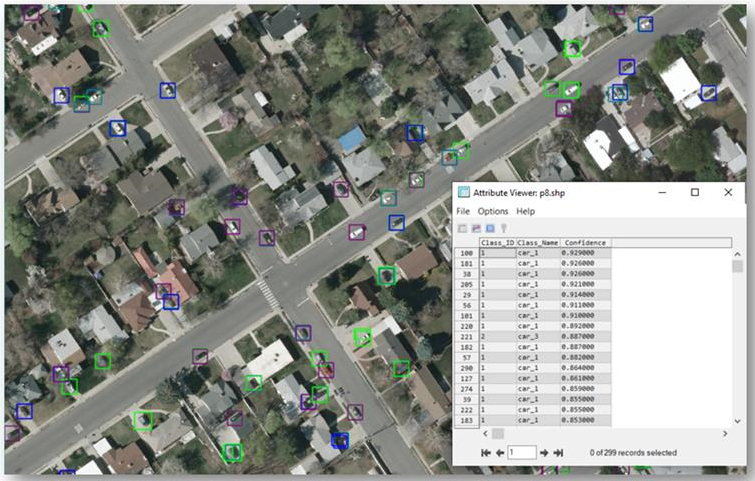
The following image shows an example of using object detection to locate different classes of vehicles:
Process Overview
The object detection process involves the following steps:
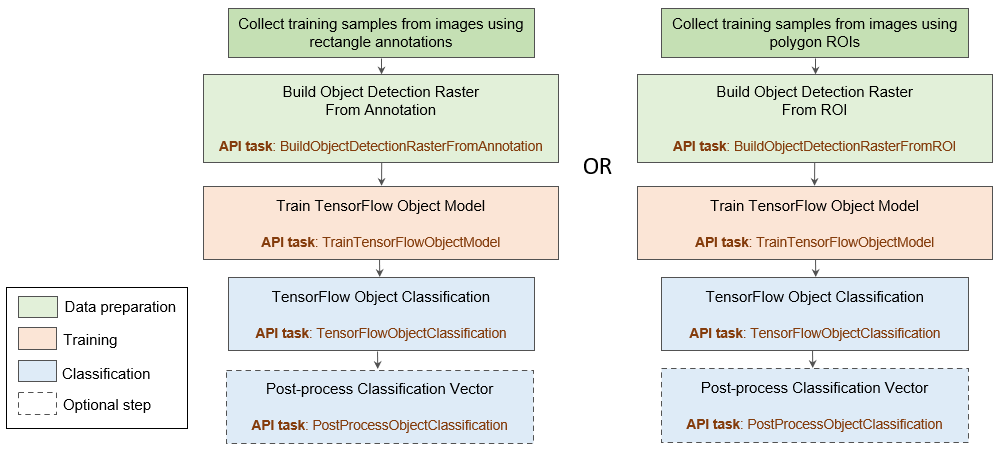
See the following topics for more information on each step:
See Also
Overview of ENVI Deep Learning
, Label Features, View Object Detection Raster Labels