The IMSL_COVARIANCES function computes the sample variance-covariance or correlation matrix.
This routine requires an IDL Advanced Math and Stats license. For more information, contact your sales or technical support representative.
The IMSL_COVARIANCES function computes estimates of correlations, covariances, or sum of squares and crossproducts for a data matrix x. The means, (corrected) sum of squares, and (corrected) sums of crossproducts are computed using the method of provisional means.
Let:
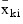
denote the mean based on i observations for the k-th variable, fi and wi denote the frequency and weight of the i-th observation, respectively, and let cjki denote the sum of crossproducts (or sum of squares if j = k) based on i observations. Then, the method of provisional means finds new means and sums of crossproducts shown in the example below.
The means and crossproducts are initialized as:
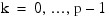
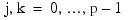
where p denotes the number of variables. Letting xk, i + 1 denote the k-th variable on observation i + 1, each new observation leads to the following updates for:
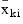
and cjki using update constant ri + 1:
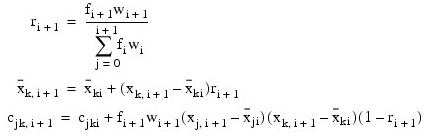
Syntax Notes
The IMSL_COVARIANCES function uses the following definition of a sample mean:
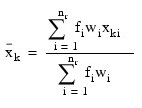
where nr is the number of cases. The formula below defines the sample covariance, sjk, between variables j and k.
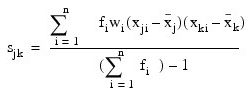
The sample correlation between variables j and k, rjk, is defined below:
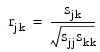
Example
This example illustrates the use of IMSL_COVARIANCES for the first 50 observations in the Fisher iris data (Fisher 1936). Note that the first variable is constant over the first 50 observations.
x = IMSL_STATDATA(3)
x = x(0:49, *)
cov = IMSL_COVARIANCES(x)
IDL prints:
0.00000 0.00000 0.00000 0.00000 0.00000
0.00000 0.124249 0.0992163 0.0163551 0.0103306
0.00000 0.0992163 0.143690 0.0116980 0.00929796
0.00000 0.0163551 0.0116980 0.0301592 0.00606939
0.00000 0.0103306 0.00929796 0.00606939 0.0111061
Errors
Warning Errors
STAT_CONSTANT_VARIABLE: Correlations are requested, but the observations on one or more variables are constant. The corresponding correlations are set to NaN.
Syntax
Result = IMSL_COVARIANCES(x [, /DOUBLE] [, VAR_COVAR=value] [, CORRECTED_SSCP=value] [, CORRELATION=value] [, STDEV_CORRELATION=value] [, FREQUENCIES=array] [, INCIDENCE_MAT=variable] [, MISSING_VAL=value] [, MEANS=variable] [, NMISSING=variable] [, NOBS=variable] [, SUM_WEIGHTS=variable] [, WEIGHTS=array])
Return Value
If no keywords are used, IMSL_COVARIANCES returns a two-dimensional matrix containing the sample variance-covariance matrix of the observations in which value in element (i, j) corresponds to the sample covariance between the i-th and j-th variable.
Arguments
x
Two-dimensional matrix containing the data. The data value for the i-th observation of the j-th variable should be in x(i,j).
Keywords
DOUBLE (optional)
If present and nonzero, double precision is used.
VAR_COVAR (optional)
Variance-covariance matrix (default). Use only one of the following keywords to specify the type of matrix to be computed: VAR_COVAR, CORRECTED_SSCP, CORRELATION, STDEV_CORRELATION.
CORRECTED_SSCP (optional)
Corrected sum-of-squares and crossproducts matrix. Use only one of the following keywords to specify the type of matrix to be computed: VAR_COVAR, CORRECTED_SSCP, CORRELATION, STDEV_CORRELATION.
CORRELATION (optional)
Correlation matrix. Use only one of the following keywords to specify the type of matrix to be computed: VAR_COVAR, CORRECTED_SSCP, CORRELATION, STDEV_CORRELATION.
STDEV_CORRELATION (optional)
Correlation matrix, except for diagonal elements which are standard deviations. Use only one of the following keywords to specify the type of matrix to be computed: VAR_COVAR, CORRECTED_SSCP, CORRELATION, STDEV_CORRELATION.
FREQUENCIES (optional)
Array containing the vector of frequencies for the observation. Default: all observations have a frequency of 1.
INCIDENCE_MAT (optional)
Named variable into which the incidence matrix is stored. If MISSING_VAL is 0, the number of valid observations is returned through this keyword; otherwise, the nvar x nvar matrix (where nvar is the number of variables in x) contains the number of pairs of valid observations used in calculating the crossproducts for covariance.
MISSING_VAL (optional)
Scalar integer which defines the method used to exclude missing values in x from the computations, where NaN is interpreted as the missing value code. The methods are as follows:
- 0: The exclusion is listwise. (The entire row of x is excluded if any of the values of the row is equal to the missing value code.)
- 1: Raw crossproducts are computed from all valid pairs and means, and variances are computed from all valid data on the individual variables. Corrected crossproducts, covariances, and correlations are computed using these quantities.
- 2: Raw crossproducts, means, and variances are computed as in the case of MISSING_VAL = 1. However, corrected crossproducts and covariances are computed only from the valid pairs of data. Correlations are computed using these covariances and the variances from all valid data.
- 3: Raw crossproducts, means, variances, and covariances are computed as in the case of MISSING_VAL = 2. Correlations are computed using these covariances, but the variances used are computed from the valid pairs of data.
MEANS (optional)
Named variable into which array containing the means of variables in x is stored. The i-th components of the array correspond to x(*, i).
NMISSING (optional)
Specifies a variable into which the total number of observations that contain any missing values (NaN) is stored.
NOBS (optional)
Named variable into which the sum of the frequencies is stored. If MISSING_VAL is 0, observations with missing values are not included in Nobs; otherwise, all observations are included except for observations with missing values for the weight or the frequency.
SUM_WEIGHTS (optional)
Specifies a variable into which the sum of the weights of all observations is stored. If keyword MISSING_VAL is equal to 0, observations with missing values are not included in Sum_weights. Otherwise, all observations are included except for observations with missing values for the weight or the frequency.
WEIGHTS (optional)
Array containing the vector of weights for the observation. Default: all observations have equal weights of 1.
Version History