In a computer, real numbers are represented with finite precision. While in most cases it is safe to assume that the result of an arithmetic operation done on your computer is correct, it is important to remember that this finite-precision representation leads to unavoidable errors, especially when floating-point numbers, which are digital approximations to real numbers, are involved.
Note: Before using floating-point numbers, we recommend getting a clear view of your data so that you can then understand what level of precision you need. The rest of this topic gives some background on the implications of using floating-point numbers in your arithmetic operations.
Note: The accuracy of both single and double precision numbers in IDL depends upon both the platform and compiler. Since IDL is written in C, numbers in IDL will behave identically with a program written in C on your platform. For details on the compiler and compile flags for your platform, you can examine the !MAKE_DLL system variable.
To understand why floating-point numbers are inherently inaccurate, consider the following:
- Floating-point numbers must be made to fit in a space (a string of binary digits in a computer’s memory register) that can only hold an integer and a scaling factor.
- Floating-point numbers are represented by strings of a limited number of bits, but represent numbers much larger or smaller than that number of digits can be made to express.
In other words, floating-point values are finite-precision approximations of infinitely precise numbers.
For example, some numbers are exactly representable by single-precision floating point numbers:
PRINT, 2.0, FORMAT='(f25.16)'
PRINT, 2.0 EQ 2.0d ? 'true' : 'false'
IDL displays:
2.0000000000000000
true
Other numbers are not exactly representable:
PRINT, 0.1, FORMAT='(f25.16)'
PRINT, 0.1 EQ 0.1d ? 'true' : 'false'
IDL displays:
0.1000000014901161
false
Because of these differences, when using many of IDL's math routines, note that calling them with single versus double precision floating-point numbers may give slightly different results.
For more information on floating point numbers, refer to the IEEE Standard for Floating-Point Arithmetic (IEEE 754), summarized on Wikipedia.org.
Roundoff Error
When working with floating-point arithmetic, it is helpful to consider the quantity known as the machine accuracy or the floating-point accuracy of your particular computer. This is the smallest number that, when added to 1.0, produces a floating-point result that is different from 1.0.
A useful way of thinking about machine accuracy is to consider it to be the fractional accuracy to which floating-point numbers are represented. In other words, the machine accuracy roughly corresponds to a change of the least significant bit of the floating-point mantissa—precisely what can happen if a number with more significant digits than fit in the floating-point mantissa is rounded to fit the space available. Generally speaking, every floating-point arithmetic operation introduces an error at least equal to the machine accuracy into the result. This error is known as roundoff error.
Roundoff errors are cumulative. Depending on the algorithm you are using, a calculation involving n arithmetic operations might have a total roundoff error between SQRT(n) times the machine accuracy and n times the machine accuracy.
Note that the machine accuracy is not the same as the smallest floating-point number your computer can represent. To find these and other machine-dependent quantities for your own computer, see MACHAR.
Truncation Error
Another type of error is also present in some numerical algorithms. Truncation error is the error introduced by the process of numerically approximating a continuous function by evaluating it at a finite number of discrete points. Often, accuracy can be increased (again at some cost of computation time) by increasing the number of discrete points evaluated.
For example, consider the process of calculating
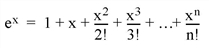
Obviously, the answer becomes more accurate as n approaches infinity. When performing the actual computation, however, a cutoff value must be specified for n. Increasing n reduces truncation error at the expense of computational effort.
Several IDL routines allow you to specify cutoff values in such cases (see, for example, INT_2D. When writing your own routines in IDL, it is important to consider this trade-off between accuracy and computational time.
Routines for Mathematical Error Assessment
Below is a brief description of IDL routines for checking math error status and machine characteristics.
|
Routine |
Description |
|
CHECK_MATH
|
Returns and clears accumulated math error status.
|
|
FINITE
|
Returns True if its argument is finite.
|
|
MACHAR
|
Determines and returns machine-specific parameters affecting floating-point arithmetic.
|
Accuracy and Floating Point Operation References
Burden, Richard L., J. Douglas Faires, and Albert C. Reynolds. Numerical Analysis. Boston: PWS Publishing, 1993. ISBN 0-534-93219-3
Goldberg, David. "What Every Computer Scientist Should Know About Floating-Point Arithmetic" in Computing Surveys, March 1991. Association for Computing Machinery, Inc.
Stoer, J., and R. Bulirsch. Introduction to Numerical Analysis. New York: Springer-Verlag, 1980. ISBN 0-387-90420-4
Press, William H. et al. Numerical Recipes in C: The Art of Scientific Computing. Cambridge: Cambridge University Press, 1992. ISBN 0-521-43108-5